先日、「MD5の変換/逆変換を行うサイト」を作成した後に以下の記事を読んでパスワードに大文字を使うことはあまりないのではという考えに至りました。
最悪のパスワード2018年ランキング、‘donald’が23位でデビュー | TechCrunch Japan
ランダムに生成されるものを除いて、パスワードって半角英数字だけを使用することが多い気がします。ということでA-Zの26文字を除いて0-9a-zの36文字のみを使用した「MD5の変換/逆変換を行うサイト(36進数版)」を作り直すことにしました。
36進数版の変更点
稼働中の62進数版のサイトは現在5桁の辞書データの作成中です。データのインサート自体は特にパフォーマンスの低下もなく行えていますが、新しく作るサイトの方では以下の点を変更してみました。
- 逆変換可能な文字の最大桁は8桁を想定
- MD5ハッシュ化前のキーを格納するカラムに入る値は1~8文字なので可変長文字型のvarchar(8)とする
- テーブルだけでなくもDBも16^2個作成する(後述)
- MD5ハッシュ文字列を格納するカラムにはDB名とテーブル名のサフィックスを含めない
- DB名のサフィックスは1,2文字目の2文字とする
- テーブル名のサフィックスは3,4文字目の2文字とする(これは前回と同様)
- 先頭4文字がテーブル内のレコードで同一となるのでMD5ハッシュ文字列を格納するカラムの型は先頭4文字を除いた28文字を格納できる固定長型のchar(28)とする
DBについて
8桁の36進数の全通りをDBに突っ込もうとした場合、レコードの総数は36^8で2,821,109,907,456(約2.8兆)となります。
2.8兆レコードのデータを保持できる方法を考えた結果これまでの256テーブルに分けるだけでは1テーブルのレコード数が11,019,960,576(約110憶)となりなんとなくダメな気がする。
そこでDBを分割するという手法を考えてみました。
一見するとDBを分けずとも16^2のテーブル数をさらに16^3や16^4の数に変更するだけで良いようにも見えますが、調べてみた感じパフォーマンスを落とさずに使えるテーブルの上限がある模様。Windowsで同一のフォルダにファイルが大量にあると開くのが遅くなることがあるのと同じような原因のようです。
16^3の時点で4,096となってしまうためDB辺りのテーブル数はこれまでと同じにすることにしました。
参考:漢(オトコ)のコンピュータ道: 限界までMySQLを使い尽くす!!
話は戻り、2.8兆のデータが登録された状態で1テーブルあたりのレコード数は2,821,109,907,456 / 256(DB数) / 256(テーブル数)という計算により、43,046,721(約4300万)となります。これくらいのレコード数ならなんとなく大丈夫な気がする(^^;
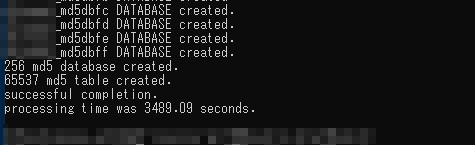
プログラムで256DBと256テーブルを作成してみたときの処理時間ですがなんと58分も掛かってました。実行したPCがいつものデスクトップPC(i7-4770K)ではなくノートPC(i7-8550U)なことを考慮しても掛かりすぎな気がする。
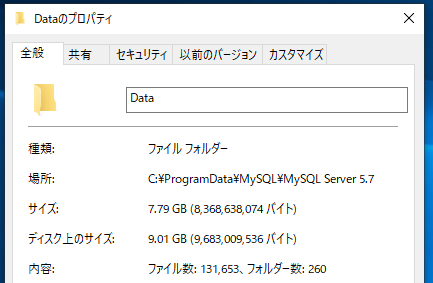
こちらは作成した直後の256個のDBを含むデータディレクトリのサイズです。既存のMySQLと共存させるのは何となく嫌だったので別途MySQL5,7をローカルにインストールしています。information_schemaとかmysqlとかその辺のDBは含まれますが空のDBだけでこれだけ容量食うとは思わなかった。
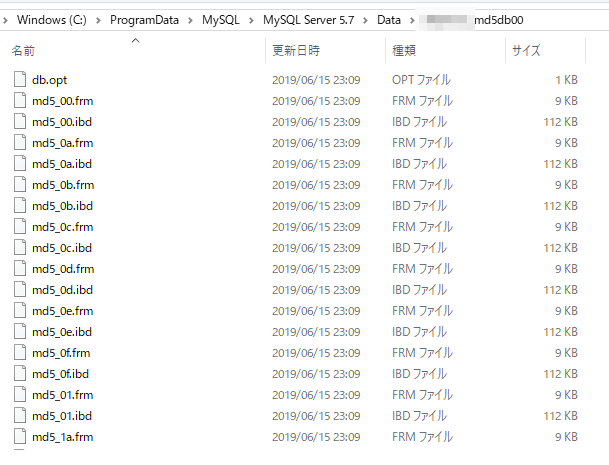 DBの中身はこんな感じでした。テーブルごとにibdファイルとfrmファイルが存在することがわかります。1ファイルあたりのサイズはそんなに大きくないですがちりつもで1DBあたりだと35MBほどありました。
DBの中身はこんな感じでした。テーブルごとにibdファイルとfrmファイルが存在することがわかります。1ファイルあたりのサイズはそんなに大きくないですがちりつもで1DBあたりだと35MBほどありました。
データディレクトリの各ファイルの役割は以下が参考になりました。
参考:MySQLのデータディレクトリの内容とその役割について | colori
辞書データを作成するプログラムについて
62進数版のときはデータのインサートにWordPressのwpdbを使用していましたが、DBの削除やgrantなどのSQLがうまくいかなかったためmysqliを使用する形に変更してみました。
参考:[PHP] mysqli使い方まとめ(MySQL接続~SELECT実行まで) – Qiita
参考:mysqliのトランザクション | GRAYCODE PHPプログラミング
参考:php – MySqli: is it possible to create a database? – Stack Overflow
以下が作成したMD5辞書データの作成プログラムのmysqli版になります。
global $wpdb;
try {
// コマンドライン引数から登録する件数を取得
$insert_count = get_md5_insert_count(1000, $argc, $argv);
// トランザクションを開始
$wpdb->query("START TRANSACTION");
// 現在の登録数を取得
$result = $wpdb->get_col("SELECT count FROM md5_counter");
if (is_null($result) || count($result) <= 0) {
throw new Exception("select md5_counter error.");
}
$start_count = intval($result[0]);
// データインサート用のコネクションを作成
$mysqli_conn = create_mysqli_connection();
if ($mysqli_conn->connect_error) {
throw new Exception("mysqli connect failed.");
}
// トランザクション開始
$mysqli_conn->begin_transaction();
// 引数で指定した件数分処理
$register_count = 0;
$end_count = $start_count + $insert_count;
for ($i = $start_count; $i < $end_count; $i++) {
$md5_before = dec_to_b36($i);
$md5_after = md5($md5_before);
// 先頭2文字をもとにインサート先のDB名を取得
$database_name = MD5_DB_PREFIX . substr($md5_after, 0, MD5_DB_SUFFIX_NUM);
// 3,4文字目を抽出してインサート先のテーブル名を取得
$table_name = "md5_" . substr($md5_after, MD5_DB_SUFFIX_NUM, MD5_TABLE_SUFFIX_NUM);
// テーブルに格納するデータは4文字目以降の28桁
$md5_after = substr($md5_after, (MD5_DB_SUFFIX_NUM + MD5_TABLE_SUFFIX_NUM));
// インサート処理
$query = "INSERT INTO {$database_name}.{$table_name}(md5_key, md5_hash_remain) values ('{$md5_before}', '{$md5_after}')";
if ($mysqli_conn->query($query) !== TRUE) {
throw new Exception("insert error.\nquery : " . $query);
}
$register_count++;
}
// カウンタを更新
$wpdb->update("md5_counter", ['count' => $start_count + $register_count], ['id' => 1]);
// DBをコミット
$wpdb->query('COMMIT');
// mysqliコネクションをコミットして閉じる
$mysqli_conn->commit();
$mysqli_conn->close();
} catch (Exception $e) {
// DBをロールバック
$wpdb->query("ROLLBACK");
if ($mysqli_conn != null) {
try {
$mysqli_conn->rollback();
$mysqli_conn->close();
} catch (Exception $e2){
}
}
}wpdbを使用していた箇所のうち必要な個所を部分的にmysqliに置き換えただけです。変えなくてもいい箇所はめんどくさかったのでそのままにしておきました(^^;
mysqliを使ったインサート処理についてINSERT INTO [DB名].[テーブル名]のような指定をすることで1つのコネクションで操作できました。mysqliのコネクションは全てのDBへのアクセス権限を持つrootで作成しています。
実際に2桁までの辞書データを作成してみた

上に載せたプログラムを実行してみたところ62進数版の頃と比べて処理時間が大きく増えてしまいました。
62進数版の方は8億レコードほど登録している状態でも10万件の登録を18秒程度で行えていますが、こちらはたったの1294レコード登録するのに47秒も掛かってしまっています。
このバッチ処理自体はノートPCで行っており動作させている環境が違うというのが理由の一つに考えられますがそれを考慮しても遅い気がする。
DB作りすぎたのかもしれない???
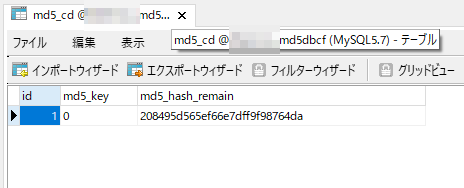
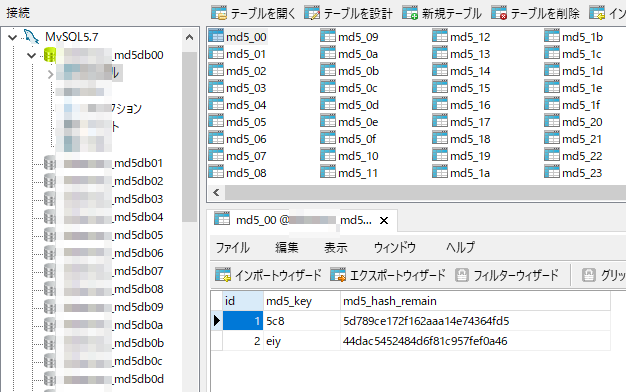
データ自体は意図したとおり入っていることを確認。1レコード目はMD5ハッシュ化前の文字列が「0」のためMD5ハッシュ化した文字列は「cfcd208495d565ef66e7dff9f98764da」となります。
1,2文字目をDB名に使用し3,4文字目をテーブル名に使用しているためハッシュデータを格納するカラムには残りの28文字が入っていることがわかります。
続けて3桁の辞書データを作成してみた
遅い原因がはっきりしないのでとりあえず続けて3桁目を登録してみました。
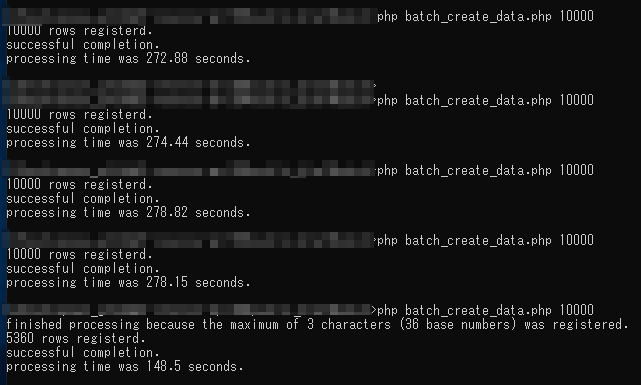
1万件の登録処理に270秒ほど掛かりました。2桁目の登録の時と同様にだいぶ遅い。
何度かバッチを呼び出して36^3の46,656件のデータが登録されました。
テーブルの総数が65,536なのでまだ空のテーブルもあるはず。
思考停止して4桁目の辞書データを作成してみた
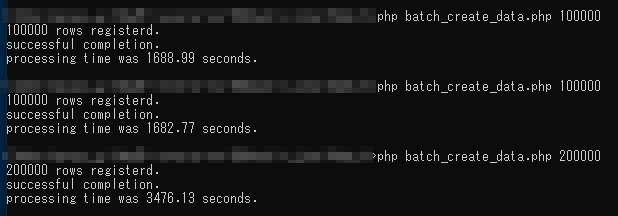
10万件の登録に30分弱掛かっています。。
この辺であまりにも遅いのでどうにかしようとプログラムを見直し、とりあえずバルクインサートを行うよう修正することにしました。
バルクインサート処理への代替について
プログラムは以下のように書き換えました。
// 256MB
ini_set('memory_limit', 268435456);
$insert_data = [];
for ($i = $start_count; $i < $end_count; $i++) {
$md5_before = dec_to_b36($i);
$md5_after = md5($md5_before);
$database_name = MD5_DB_PREFIX . substr($md5_after, 0, MD5_DB_SUFFIX_NUM);
$table_name = "md5_" . substr($md5_after, MD5_DB_SUFFIX_NUM, MD5_TABLE_SUFFIX_NUM);
$md5_after = substr($md5_after, (MD5_DB_SUFFIX_NUM + MD5_TABLE_SUFFIX_NUM));
// バルクインサート用の配列データに格納
if (!array_key_exists($database_name, $insert_data)) {
$insert_data[$database_name] = [];
}
if (!array_key_exists($table_name, $insert_data[$database_name])) {
$insert_data[$database_name][$table_name] = [];
}
$insert_data[$database_name][$table_name][$md5_before] = $md5_after;
}
// バルクインサート処理
if (!empty($insert_data)) {
foreach ($insert_data as $database_name => $table_data) {
foreach ($table_data as $table_name => $record_data) {
$query = "INSERT INTO {$database_name}.{$table_name}(md5_key, md5_hash_remain) values";
$bulk_data = [];
foreach ($record_data as $key => $value) {
$bulk_data[] = "('{$key}', '{$value}')";
}
$query .= implode(",", $bulk_data);
$bulk_insert_count = count($bulk_data);
if ($mysqli_conn->query($query) !== TRUE) {
throw new Exception("insert error.\nquery : " . $query);
}
$register_count += $bulk_insert_count;
}
}
}同じテーブルへのインサートを1個のクエリにまとめています。
バルクインサートについては気を付けなければいけないこととしてPHPのメモリ上限の問題があります。
一度MD5の辞書データを大きな配列データに格納しているためそこでメモリを大きく消費してしまいます。そのため先頭でPHPのメモリ上限を256MBまで増やしておきました。
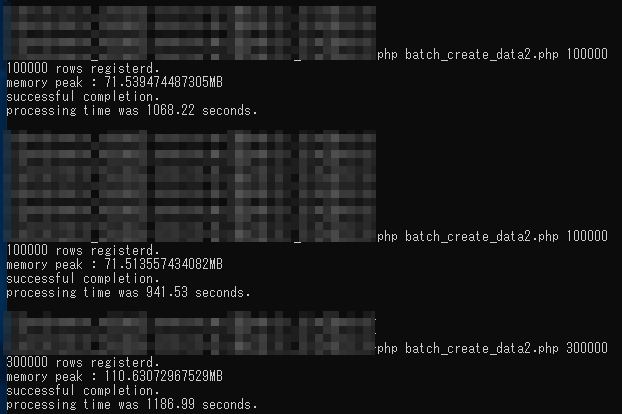
バルクインサートによって10万件当たりの処理時間が1700秒から1000秒程度に短縮されました。
SQLの発行回数が10万回だったのがいくらか減ったことが要因と考えられます。
ただし、1回のバッチによる処理件数が少ないと結果として発行されるインサートの回数が変わらず効果が得られないことも考えられます。これは、30万件処理したときの処理時間が10万件処理したときの時間とあまり変わっていないことからも多分間違いなさそう。
バルクインサートの場合、256DB×256テーブルで一番多くても65536回のインサートクエリでデータ登録が行える計算となります。そのため1回あたりの処理件数は50~100万くらいがよさそう。
ちなみにOracleでは別々のテーブルへのインサートも1つにまとめるマルチテーブル・インサートということができるらしいです。MySQLは対応していない模様。仮にこれができたとして解決するかは不明。
参考: SQLクリニック(12): 1つのSQL文で複数の表にINSERTする絶品テクニック (1/2)
バルクインサートによって多少改善はされましたが正直まだ遅いと思います。
一応、解決できそうな方法としてLOAD DATA INFILE構文によるCSVデータ取り込みを検討中です。
4桁目の辞書データの作成が完了した状態のDBについて
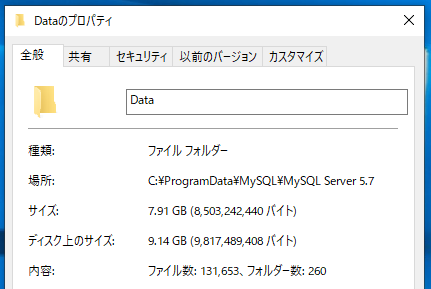
ディスク上のサイズは130MBしか増えていませんでした。
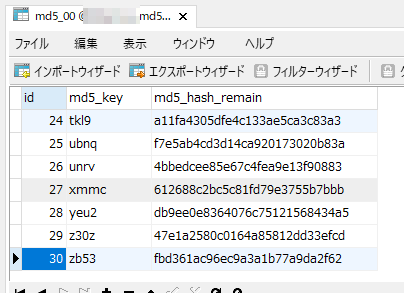
適当に開いたテーブルには30レコードしか入ってませんでした。
36^4で1,679,616レコードになりますが65,536テーブルに分散してるので妥当な数字といえると思います。
ここまでの問題点、課題点などまとめ
- ローカルのMySQL5.7の起動に数分掛かるようになってしまった(^^;
- 空のDBの状態で9GBほどの容量が必要
- データ登録がとにかく遅い
- バルクインサートに変更することで少しだけ改善できたがまだ遅い